[ХзХЉШІИЏ] LGДТ AIПЌБИПјРЬ НУАЂ AIПЭ О№Ою AIРЧ РЖЧе ЦЎЗЛЕхИІ СжЕЕЧЯБт РЇЧи Рќ ММАш AI ПЌБИРкИІ ДыЛѓРИЗЮ 2Пљ 1РЯКЮХЭ 4Пљ ИЛБюСі ПТЖѓРЮРИЗЮ ‘СІЗЮМІ РЬЙЬСі ФИМХДз(Zero-Shot Image Captioning)’РЛ СжСІЗЮ ‘AIАЁ УГРН КЛ РЬЙЬСіИІ ОѓИЖГЊ СЄШЎЧЯАд РЬЧиЧЯАэ МГИэЧЯДТСі ЦђАЁ’ЧЯДТ ДыШИ ‘LG БлЗЮЙњ AI УЇИАСі’ИІ АГУжЧбДйАэ 31РЯ ЙрЧћДй.
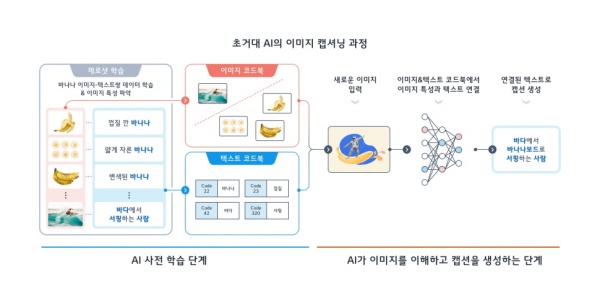
‘СІЗЮМІ РЬЙЬСі ФИМХДз’РК AIАЁ ИЖФЁ ЛчЖїРЧ НУАЂ РЮСі ДЩЗТУГЗГ УГРН КЛ ЛчЙАРЬГЊ, ЕПЙА, ЧГАц ЕюРЬ ЦїЧдЕЧОю РжДТ РЬЙЬСіИІ КУРЛ ЖЇГЊ РЯЗЏНКЦЎЗЙРЬМЧ, БзЗЁЧШ Ею ЧЅЧі ЙцНФРЬ ДйИЅ РЬЙЬСіИІ КУРЛ ЖЇ БтСИ ЧаНРЧб ЕЅРЬХЭИІ БтЙнРИЗЮ НКНКЗЮ РЬЧиЧЯАэ РЏУпЧб АсАњИІ ХиНКЦЎЗЮ МГИэЧв Мі РжДТ БтМњРЬДй.
ХфГЂИІ Чб ЙјЕЕ КЛ РћРЬ ОјДТ ЛчЖїРЬ ХфГЂ ПЉЗЏ ИЖИЎПЭ АэОчРЬ Чб ИЖИЎАЁ ЧдВВ РжДТ АЭРЛ КУРЛ ЖЇ ЕПЙАЕщРЧ Л§БшЛѕПЭ ЦЏМКРЧ АјХыСЁАњ ТїРЬСЁРЛ ЧаНРЧЯАэ ‘ХфГЂЕЕ ХаРК РжСіИИ АэОчРЬПЭДТ ДйИЃАд БЭАЁ БцАэ, ЕоДйИЎАЁ ЙпДоЧпДй’ЖѓАэ МГИэЧв Мі РжДТ АЭУГЗГ ‘СІЗЮМІ РЬЙЬСі ФИМХДз’РЧ РлЕП БИСЖЕЕ РЬПЭ РЏЛчЧЯДй.
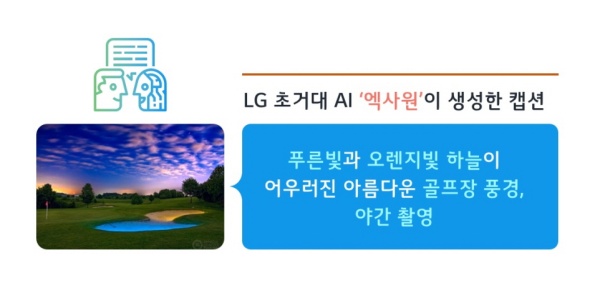 |
‘СІЗЮМІ РЬЙЬСі ФИМХДз’ БтМњРЬ СЁТї АэЕЕШЕЧИщ РЬЙЬСі РЮНФ AI БтМњРЧ СЄШЎМКАњ АјСЄМКРЬ ЧтЛѓЕЧАэ АсБЙ ЛчЖїЕщРЧ НЧЛ§ШАПЁ СїСЂРћРИЗЮ ЕЕПђРЛ Сй Мі РжДТ БтМњ АГЙпЗЮ РЬОюСњ Мі РжДй.
ПЙИІ ЕщОю, ЧЯЗчПЁЕЕ ЙцДыЧб КаЗЎРЧ РЬЙЬСі ЕЅРЬХЭЕщРЬ ПТЖѓРЮЛѓПЁ ПУЖѓПРАэ РжДТЕЅ, AIАЁ РкЕПРИЗЮ ФИМЧАњ ХАПіЕхИІ Л§МКЧи АЫЛіРЧ ЦэРЧМКАњ СЄШЎЕЕИІ ЧтЛѓНУХГ Мі РжДй. ЖЧЧб, РЧЧа РќЙЎ ЕЅРЬХЭИІ УпАЁ ЧаНРЧв АцПь РЧЧа ПЕЛѓРЛ КаМЎЧЯДТ ‘РЧЧа РќЙЎАЁ AI’ЗЮ ШАОрЧв Мі РжДй.
‘СІЗЮМІ РЬЙЬСі ФИМХДз’РК РЮАЃРЧ ЧаНР БИСЖИІ И№ЙцЧб УЪАХДы AIАЁ ЕюРхЧЯИч БтМњ ПЌБИАЁ ШАЙпЧиСіАэ РжРИИч, УжБй ШЕЮАЁ ЕЧАэ РжДТ ХиНКЦЎИІ РЬЙЬСіЗЮ КЏШЏЧЯДТ ‘Л§МКЧќ AI И№ЕЈ’РЧ МКДЩРК ЙАЗа РЬЙЬСі АЫЛіРЧ СЄШЎЕЕИІ ГєРЬДТ ЕЅЕЕ ШАПыЕЧАэ РжДй.
ЦЏШї, УжБй РкПЌОю АЫЛі КаОпПЁМ ЙнЧтРЛ РЯРИХААэ РжДТ ChatGPT УГЗГ AIАЁ НКНКЗЮ РЬЙЬСіИІ РЬЧиЧЯАэ МГИэЧЯИч, ЧиНУХТБзЕЕ До Мі РжДТ РЬЙЬСі ФИМХДз БтМњРК РЬЙЬСі АЫЛі КаОпПЁ ЧѕНХРЛ АЁСЎПУ АЭРИЗЮ ПЙЛѓЕШДй.
LGДТ ЛчЖїРЧ НУАЂ РЮСі ДЩЗТПЁ АЁБюРЬ ДйАЁМДТ 'СІЗЮМІ РЬЙЬСі ФИМХДз'РЬ РЬЙЬСіИІ ХиНКЦЎЗЮ ЧЅЧіЧЯАэ, ХиНКЦЎИІ РЬЙЬСіЗЮ НУАЂШЧв Мі РжДТ УЪАХДы ИжЦМИ№До AIРЮ ‘ПЂЛчПј(EXAONE)’РЧ БтМњ АГЙп Л§ХТАшПЁ ХЉАд БтПЉЧв АЭРИЗЮ БтДыЧЯАэ РжДй.
LG AIПЌБИПјРК АјЕППЌБИМОХЭИІ МГИГЧи УЪАХДы ИжЦМИ№До AIРЮ ‘ПЂЛчПј(EXAONE)’РЛ ПЌБИ СпРЮ ‘МПяДыЧаБГ AIДыЧаПј’, РЬЙЬСі ФИМХДз AIРЧ ЛѓПыШ МКёНКИІ АјЕПРИЗЮ СиКё СпРЮ ‘МХХЭНКХх’Ањ ЧдВВ РЬЙј АцСј ДыШИИІ СјЧрЧбДй.
ММАш УжДы БдИ№РЧ РЬЙЬСіИІ КИРЏЧб ХЉИЎПЁРЬЦМКъ ЧУЗЇЦћ БтОїРЮ МХХЭНКХхРК ЦэЧтМКАњ МБСЄМК ЕюПЁ ДыЧб AI РБИЎ АЫСѕРЛ ГЁГН АэЧАСњРЧ РЬЙЬСі-ХиНКЦЎ ЕЅРЬХЭМТ 26,000АГИІ ЙЋЗсЗЮ СІАјЧбДй.
ЧиДч ЕЅРЬХЭМТРК ЛчСј Лг ОЦДЯЖѓ РЯЗЏНКЦЎЗЙРЬМЧ, БзЗЁЧШ Ею ДйОчЧб ЧќХТРЧ РЬЙЬСіИІ ЦїЧдЧЯАэ РжОю ДыШИ ТќАЁРкЕщРК РњРлБЧАњ КёПы, ЧАСњПЁ ДыЧб АэЙЮ ОјРЬ РкНХЕщРЧ AI И№ЕЈ УжРћШПЭ МКДЩ ЦђАЁИІ СјЧрЧв Мі РжДй.
 |
РЬАцЙЋ МПяДы AIДыЧаПј МЎСТБГМіДТ “РЬЙЬСі ФИМХДзРК ПЕЛѓПЁ ГЊПРДТ АДУМЕщРЧ АќАшКЮХЭ ЛѓШВАњ ЙЎИЦБюСі РЬЧиЧи РЮАЃРЧ О№ОюЗЮ ЧЅЧіЧЯАэ МГИэЧЯАд ЧЯДТ АЭРИЗЮ AIАЁ РЮАЃРЧ СіДЩПЁ ОѓИЖГЊ АЁБюПіСГДТСі КИПЉСжДТ ЧЯГЊРЧ УДЕЕ”ЖѓИч, “ЧаНР ЕЅРЬХЭ ОјРЬЕЕ РЬЗЏЧб РлОїРЛ МіЧрЧЯДТ СІЗЮМІ РЬЙЬСі ФИМХДзРК ИХПь ЕЕРќРћРЮ ЙЎСІРЬРк ММАшРћРИЗЮЕЕ УжБйПЁ ПЌБИАЁ НУРлЕШ КаОпЗЮ LG AIПЌБИПјАњ МПяДы AIДыЧаПј, МХХЭНКХхРЬ ММАш УжУЪЗЮ УЇИАСіПЭ ПіХЉМЅРЛ АјЕП СјЧрЧЯДТ АЭРК ПьИЎГЊЖѓРЧ AI ПЊЗЎРЬ РЬЙЬ ММАшРћРЮ МіСиПЁ ЕЕДоЧпДйДТ АЭРЛ РЧЙЬЧЯИч ЖЧЧб БЙСІРћ ИЎДѕНЪРЛ ДѕПэ ГєРЬДТ АшБтАЁ ЕЩ АЭРИЗЮ Л§АЂЧбДй”Аэ ИЛЧпДй.
LG AIПЌБИПјРК ПУЧи 6Пљ ФГГЊДй ЙъФэЙіПЁМ ПИЎДТ ФФЧЛХЭ КёРќ КаОп ММАш УжАэ БЧРЇ ЧаШИРЮ ‘CVPR(Computer Vision and Pattern Recognition) 2023’ПЁМ ‘СІЗЮМІ РЬЙЬСі ФИМХДз ЦђАЁРЧ ЛѕЗЮПю АГУДРкЕщ(New Frontiers for Zero-Shot Image Captioning Evaluation)’РЛ СжСІЗЮ ПіХЉМЅРЛ СјЧрЧбДй.
LG AIПЌБИПјРК БИБл, ИЖРЬХЉЗЮМвЧСЦЎ ЕюПЁМ AI ПЌБИИІ СјЧрЧЯАэ РжДТ ЛъОїАш РќЙЎАЁЕщРЛ КёЗдЧи БлЗЮЙњ МЎЧаЕщАњ ЧдВВ РЬЙЬСі ФИМХДз БтМњ ПЌБИРЧ ЙцЧтМКАњ ШЎРхМК, AI РБИЎ ЙЎСІПЁ АќЧи НЩЕЕ РжДТ ГэРЧИІ СјЧрЧв АшШЙРЬДй.
‘LG БлЗЮЙњ AI УЇИАСі’ УжСО МіЛѓЦРРК РЬГЏ ПіХЉМЅПЁМ МКАњИІ ЙпЧЅЧв БтШИАЁ СжОюСјДй.
БшНТШЏ LG AIПЌБИПј КёРќЗІРхРК “LG AIПЌБИПјРК ЧіРч Л§МКЧќ AI Лг ОЦДЯЖѓ, АДУМИІ РЮНФЧЯДТ БтМњ МіСиРЛ ГбОю РЮАЃ МіСиРИЗЮ ПЕЛѓБюСі РЬЧиЧЯДТ AIЗЮ ФіХв СЁЧСЧв Мі РжДТ АЁДЩМКРЛ ШЎРЮЧпДй”ИщМ “ММАшРћРЮ ЧаШИПЁМ ПЕЛѓ РЬЧиРЧ ЧйНЩ БтМњРЬРк БтЙн БтМњРЮ РЬЙЬСі ФИМХДзРЛ СжСІЗЮ ДыШИИІ АГУжЧб АЭРК LGАЁ ФФЧЛХЭ КёРќ КаОпРЧ БлЗЮЙњ РдСіИІ КИПЉСи АшБтРЬИч, РЬЙј ДыШИИІ ХыЧи Рќ ММАш AI ПЌБИРкЕщАњ ЧдВВ ПЌБИРЧ РЧРЧПЭ ЧЪПфМК, БзИЎАэ ШЎРх АЁДЩМКПЁ АќЧи ЧдВВ ГэРЧЧЯДТ РхРЛ ИИЕщАэРк ЧбДй”Аэ ИЛЧпДй.
#LG #AI #БлЗЮЙњ AI УЇИАСі #СІЗЮМІ РЬЙЬСі ФИМХДз #ПЂЛчПј #РЬЙЬСі РЮНФ
РЏЛѓШЦ БтРк thtower1@techholic.co.kr
<РњРлБЧРк © ХзХЉШІИЏ, ЙЋДм РќРч Йз РчЙшЦї БнСі>
 СОБйДч, РЧДыСѕПј АЅЕю Мг, ШІЗЮ ОрСј-МвКёРкЕщ ИЖРН СІРЯ ИЙРЬ ШЩУЦДй
СОБйДч, РЧДыСѕПј АЅЕю Мг, ШІЗЮ ОрСј-МвКёРкЕщ ИЖРН СІРЯ ИЙРЬ ШЩУЦДй
 ЙЬЗЁПЁМТРкЛъПюПы, кИХѕРк ETF 2СО МјРкЛъ 6СЖ ЕЙЦФ
ЙЬЗЁПЁМТРкЛъПюПы, кИХѕРк ETF 2СО МјРкЛъ 6СЖ ЕЙЦФ






















