 |
ПЃКёЕ№ОЦАЁ РкЛч GPU АГЙпРк ФСЦлЗБНКРЮ GTC 2016 БтАЃ Сп ТїММДы GPU ОЦХАХиУГРЮ ЦФНКФЎ(Pascal)РЛ БтЙнРИЗЮ Чб GPU ФЈРЮ GP100РЛ АјНФ ЙпЧЅЧпДй. GP100РЛ УЄХУЧб УЙ СІЧАРК GP100РЛ РћПыЧбХзННЖѓ P100РЬДй.
ПЃКёЕ№ОЦАЁ АСЖЧЯДТ GP100РЧ 5АЁСі ЦїРЮЦЎДТ ЦФНКФЎ ОЦХАХиУГПЭ 16nm ЧЩЦъ(FinFET) СІСЖАјСЄ, HBM2 ИоИ№ИЎ БтМњАњ ЧСЗЮМММАЃ ПЌАсРЛ РЇЧб РЮХЭЦфРЬНКРЮ NVИЕХЉ(NVLink), AI ОЫАэИЎСђРЬДй.
GP100РЧ АЁРх ХЋ ЦЏТЁ АЁПюЕЅ ЧЯГЊДТ ПЊНУ GPU ИЖРЬХЉЗЮ ОЦХАХиУГИІ ЙйВхДйДТ АЭ. СІСЖАјСЄ ПЊНУ БтСИ 28nmПЁМ 16nm ЧЩЦъРИЗЮ ЙЬММШЧпДй. БзЗИДйИщ ПЉБтПЁМ ПРДТ РхСЁРК ЙЛБю. РЯДм ЦЎЗЃСіНКХЭ С§РћМі. РЬРќ ИЦНКРЃРЬ УжДы 80Оя АГПДДј ЕЅ КёЧи 153Оя АГБюСі ВјОюПУЗШДй.
 |
ЖЧ ДйИЅ РхСЁРК ЕПРл ХЌЗЯРЛ ГєРЯ Мі РжДйДТ АЭРЬДй. ХЌЗЯ МгЕЕИІ ГєРЬЗСИщ РњРќЗТРЬ ЧЪМіРЮЕЅ СІСЖАјСЄРЛ ЙЬММШЧЯИщ РњРќЗТРЛ ШЎКИЧв Мі РжДй. GP100РК ДЉМіРќЗљИІ ОяСІЧи РќЗТ ШПРВРЛ ВјОюПУЗШАэ РЬПЁ ЕћЖѓ ДчПЌШї РќЗТДч МКДЩЕЕ ГєОЦСГДй. ОеМ ЙрЧћЕэ ЕПРл ХЌЗЯ ПЊНУ БтСИ ИЦНКРЃРК 1,114MHzПДСіИИ ЦФНКФЎРК 1,480MHzБюСі ВјОюПУЗШДй. СІСЖАјСЄ ЙЬММШПЭ РЬПЁ ЕћИЅ РќЗТ ШПРВ ЧтЛѓРЬ ХЌЗЯ ЛѓНТРИЗЮ РЬОюСј АЭРЬДй. Бз Лг ОЦДЯЖѓ ЦЎЗЃСіНКХЭ МіАЁ ХЉАд ДУИщМ ПЌЛъ МКДЩРЬ ССОЦСј АЧ ЙАЗаРЬДй.
SM(Streaming Multiprocessor) МіЕЕ ДУЗШДй. SMРК НБАд Л§АЂЧЯИщ ПЌЛъРЛ РЇЧб ЧйНЩ ПЊЧвРЛ ЧЯДТ АЭРИЗЮ ПЌЛъ УжМв ДмРЇЖѓАэ Л§АЂЧЯИщ ЕШДй. SM 1АГДТ ФэДйФкОю Ию АГИІ ЙОюМ БИМКЧбДй. GP100ПЁ РжДТ SMРК 56АГДй. БтСИ ИЦНКРЃ(GM200 БтСи)РЧ АцПь SM МіДТ 24АГПДДй.
 |
ДйИИ ЦФНКФЎРЧ АцПь БтСИ ИЦНКРЃАњ КёБГЧЯИщ SMРЛ БИМКЧЯДТ ПфМвПЁДТ ТїРЬАЁ РжДй. РЯДм ЧйНЩ АнРЮ ФэДй ФкОюДТ БтСИ ИЦНКРЃРК 128АГПДСіИИ GP100РК 64АГДй. РЬПЁЕћЖѓ ФэДйФкОю РќУМ МіДТ 3,584АГДй. SMДч ФэДй ФкОю АГМіИІ СйРЮ РЬРЏДТ ЗЮПьЗЙКЇ ФкЕљРЛ ЧСЗЮБзЗЁЙжЧв ЖЇ ЕіЗЏДзПЁ АЁРх ССБт ЖЇЙЎРЬЖѓАэ ЧбДй.
ЖЧ GP100РК ЗЙСіНКХЭИІ ДУИЎДТ АЩ ХУЧпДй. ИЦНКРЃРК 1.5MBПДСіИИ GP100РК 14MBДй. БзЗИДйИщ ЗЙСіНКХЭАЁ ИЙОЦМ ССРЛ РЯРК ЙЛБю. ДчПЌЧЯСіИИ КќИЅ ЕЅРЬХЭ УГИЎДй. CPUПЭ ИЖТљАЁСіЗЮ GPU ПЊНУ ГЛКЮПЁ УГИЎИІ РЇЧб ЗЙСіНКХЭИІ АЎУпАэ РжДй. ЗЙСіНКХЭДТ ЕЅРЬХЭГЊ УГИЎСпРЮ ГЛПыРЛ РсНУ БтОяЧи ЕЮДТ АэМг РќПы ПЕПЊРЬДй. L2 ФГНУГЊ ИоИ№ИЎКИДй Дѕ КќИЅ АЧ ЙАЗа.
GP100РЬ КќИЅ УГИЎ МгЕЕИІ ШЎКИЧпДѕЖѓЕЕ РЬПЁ АЩИТРК ЗЙСіНКХЭИІ ШЎКИЧЯСі ОЪРИИщ КДИёЧіЛѓРЬ РЯОюГЏ МіЙлПЁ ОјДй. GP100РЬ ЗЙСіНКХЭ МіИІ ДУИА РЬРЏДй. GPU ПЌЛъ ФкОюРЧ ШПРВРЛ ХЉАд ГєПЉСжДТ ПфРЮРЮ АЭРЬДй. ЙАЗа GP100РК L2 ФГНУЕЕ БтСИ ИЦНКРЃРЬ 3MBПДДј ЕЅ КёЧи 4MBЗЮ ДУЗШДй.
 |
GP100РК ИоИ№ИЎЕЕ HBM(High Bandwidth Memory)2ИІ СіПј, 720GB/secПЁ ДоЧЯДТ БЄДыПЊРЛ ШЎКИЧпДй. HBM2ДТ CoWoS(Chip-on-Wafer-on-Substrate), БзЗЏДЯБю ИоИ№ИЎИІ РћУўЧЯДТ БтМњРЛ РћПыЧпДй. GP100РК ИоИ№ИЎИІ 4УўРИЗЮ НзОЦПУЗШДй. GP100 ФкОю СжКЏПЁДТ ИоИ№ИЎ ФСЦЎЗбЗЏ РЏДж 8АГАЁ РжДй. РЬДТ РћУўЧб HBM2 И№Ет 4АГДч ИоИ№ИЎ ФСЦЎЗбЗЏИІ 2АГОП ПЌАсЧб АЭРЬДй. ИоИ№ИЎ ФСЦЎЗбЗЏИЖДй ИоИ№ИЎДТ 512КёЦЎЗЮ СІОюЧбДй. 2АГИІ ЙОю 1,024КёЦЎАЁ ЕЧДТ АЭ. БтСИ ИЦНКРЃРЬ 384КёЦЎПДДйДТ СЁРЛ АЈОШЧЯИщ ШЮОР ПЉРЏ РжДТ ДыПЊЦјРЛ ШЎКИЧпДйАэ Чв Мі РжДй. ДѕБИГЊ ИЦНКРЃРК GDDR5ИІ РЬПыЧи 288GB/secПДСіИИ GP100РК CoWoS БтМњРЛ РћПыЧи 720GB/secЗЮ ЕЅРЬХЭ РЬЕП МгЕЕАЁ ШЮОР КќИЃДй.
 |
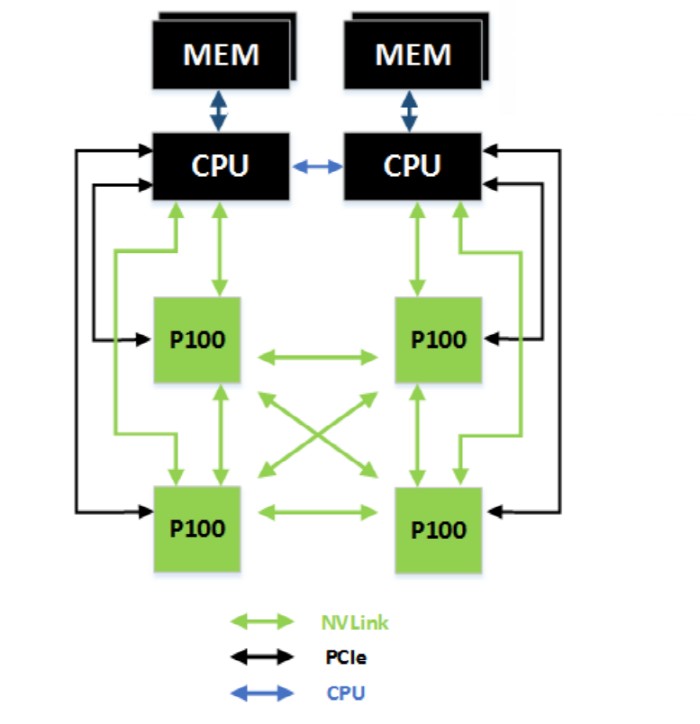
GP100РК GPUГЂИЎ ПЌАсЧЯДТ РЮХЭЦфРЬНКЗЮ NVИЕХЉ(NVlink)ИІ РЬПыЧбДй. NVИЕХЉДТ ОчЙцЧт 40GB/secЗЮ GPUИІ МЗЮ ПЌАсЧиСиДй. NVИЕХЉИІ РћПыЧб РхСЁРК GP100РЬ РЬРќКИДй ФшРћЧб GPU ШЎРхМКРЛ ДЉИБ Мі РжАд ЧиСиДйДТ АЭРЬДй. НЧСІЗЮ УЙ И№ЕЈЗЮ ГЊПТ ХзННЖѓ P100РК NVИЕХЉ 4АГИІ РЬПыЧи GPU 4АГИІ ПЌАсЧв Мі РжДй. GP100РК РЬЗИАд GPU МКДЩ Лг ОЦДЯЖѓ РЮХЭЦфРЬНК АГМБРЛ ХыЧи ИжЦМ GPU БИМКРЛ Чв Мі РжАд ЧпДй. ЙАЗа NVИЕХЉИІ СіПјЧЯДТ IBMРЬГЊ ПРЧТЦФПі СјПЕРЧ CPUПЭЕЕ GPUИІ ПЌАсЧв Мі РжДй.
 |
GP100РЧ НЧСњРћ АЁФЁДТ КЮЕПМвМіСЁ ПЌЛъ МКДЩПЁМ ПГКМ Мі РжДй. GP100РЧ 32КёЦЎ КЮЕПМвМіСЁ ПЌЛъ МКДЩРК 10.6TFLOPSДй. БтСИ ИЦНКРЃКИДй 1.5Йш АЁЗЎ ГєОЦСГРЛ ЛгРЬДй. ЧЯСіИИ ИЦНКРЃРЧ УыОрЧпДј 64КёЦЎ КЮЕПМвМіСЁ ПЌЛъЕЕ СіПјЧЯИч 5.3TFLOPSДй. Бз Лг ОЦДЯЖѓ 16КёЦЎ КЮЕПМвМіСЁ ПЌЛъРЧ АцПьПЁДТ 21.1TFLOPSПЁ ДоЧбДй. СіБнБюСі ГЊПТ GPUПЭДТ ДйИЅ КЮКаРЛ АШЧб АЭРЬДй. РЬРќ GPUПЭ ДмМј КёБГЧв Мі ОјДТ РЬРЏДй.
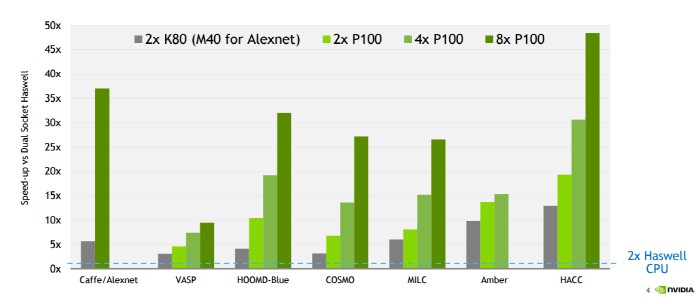
РЯЙнРћРИЗЮ ИЙРЬ ОВРЬДТ 32КёЦЎ КЮЕПМвМіСЁ ПЌЛъ Лг ОЦДЯЖѓ ПРРЯРЬГЊ АЁНК ААРК КаОпПЁМ ШАПыЧЯДТ 64КёЦЎГЊ ЕіЗЏДз ПЌЛъПЁ СпПфЧб 16КёЦЎ КЮЕПМвМіСЁ ПЌЛъ МКДЩРЛ ГєРЮ АЭ. РЬЗБ ШПАњДТ ПЃКёЕ№ОЦАЁ GP100РИЗЮ БИМКЧб ММАш УЙ ЕіЗЏДз НДЦлФФЧЛХЭИІ ЧЅЙцЧб DGX-1РЧ МКДЩРИЗЮЕЕ ШЎРЮЧв Мі РжДй. DGX-1РЛ РЬПыЧЯИщ ЕрОѓСІПТ CPU МЙіЗЮ 150НУАЃ АЩЗШДј ОЫЗКНКГн ЕіЗЏДз ШЦЗУРЛ 2НУАЃРИЗЮ СйРЯ Мі РжДйАэ ЧбДй.
 |
GP100РК РЬЗБ СЁПЁМ ПЃКёЕ№ОЦАЁ РЬРќПЁ МБКИПДДј ИЦНКРЃРЬГЊ ФЩЧУЗЏКИДй ШЮОР ЧѕНХРЧ ЦјРЬ ГєРК СІЧАРЬЖѓАэ Чв Мі РжДй. Бз Лг ОЦДЯЖѓ ЛЁЖѓСј GPU ОЦХАХиУГ БИСЖПЁ АЩИТАд ЗЙСіНКХЭГЊ L2 ФГНУ ШЎДы, HBM2 БЄДыПЊ ИоИ№ИЎПЭ NVИЕХЉИІ РЬПыЧб CPUПЭ GPUАЃ ШЄРК ИжЦМ GPU ШЎРхМКРЛ ШЎКИЧв Мі РжАд ЕЦДй. КќИЅ МгЕЕПЁ АЩИТАд КДИёЧіЛѓ ОјЕЕЗЯ СжКЏ ЕЕЗЮИІ И№ЕЮ ШЎРхАјЛчЧб МРРЬДй.
РЬЗБ СЁПЁМ КЛДйИщ ТїБт И№ЕЈРЮ КМХИ(Volta)ПЭРЧ ПЌАс АэИЎАЁ ЕЧОюСй ИИЧб ПфМвИІ АЎУпАэ РжДйАэ Чв Мі РжДй. ЕПНУПЁ ЕіЗЏДзПЁМРЧ НЧСњРћ МКДЩ ЧтЛѓРЛ ВвЧв Мі РжДТ GPUАЁ ЕюРх, РЬ НУРхПЁ ЧЪПфЧб GPUПЁ ДыЧб ЙцЧтМКРЛ СІНУЧЯАэ РжДйАэ Чв Мі РжДй.
РЬМЎПј БтРк lswcap@techholic.co.kr
<РњРлБЧРк © ХзХЉШІИЏ, ЙЋДм РќРч Йз РчЙшЦї БнСі>
 SKT, ЙАПРИЅ БтМњЗТРИЗЮ БлЗЮЙњ AIФФЦлДЯ НУДы ШАТІ ПОю
SKT, ЙАПРИЅ БтМњЗТРИЗЮ БлЗЮЙњ AIФФЦлДЯ НУДы ШАТІ ПОю
 ГнИЖКэ 'ГЊШЅЗО', ЁЎЛчРќЕюЗЯ 1200ИИ ЕЙЦФЁЏ ПјРл IP ШяЧр НХШ РеДТДй
ГнИЖКэ 'ГЊШЅЗО', ЁЎЛчРќЕюЗЯ 1200ИИ ЕЙЦФЁЏ ПјРл IP ШяЧр НХШ РеДТДй























